tomcat
图论
分子对接
两轮自平衡小车设计
子图
.md预览
matlab入门案例
unity
SylixOS
编程语言
ico
r语言
恢复显示屏异常显示的方法
产品经理常犯的错误
ps
菜鸟日记
TEMU
测试
docker 搭建es7
scrum
扩散模型
2024/4/11 15:24:37
如何获取最新diffusion models多模态方向的科研进展?
前言:我从2021年上半年开始做diffusion models,当时也只是圈内的研究者听说过有一个新的生成式模型好像还可以。没想到2022年的下半年,diffusion models火得一塌糊涂,特别是多模态方向,被stable diffusion的开源吸引了非常多的新玩家加入这一领域。可以说这一领域每天都有…

从DDPM到SDG:score-based generative models【公式推导+代码实战】
从DDPM到SDG:score-based generative models【公式推导代码实战】0、前言简称的汇总:1、原理介绍1.1Score and Score-Based Models1.2用扩散过程扰动数据Perturbing Data with a Diffusion Process1.3逆扩散过程产生基于分数的生成模型Reversing the Dif…
如何在手机端部署大型扩散模型?
Diffusion Models专栏文章汇总:入门与实战 前言:部署扩散模型面临着两个棘手的挑战:参数过大和推理时间过长,因此目前想在手机端用上扩散模型看似“奢不可求”。最近谷歌研究院的最新一项研究研究了如何把端侧部署大型扩散模型的梦想变成现实,这篇博客就和大家一起学习一下…
Image-to-Image任务的终结者:详解ControlNet原理与代码
Diffusion Models专栏文章汇总:入门与实战 前言:condition diffusion是最火爆的应用方向,2023年效果最好的几种条件diffusion models,例如《详细解读PITI:开启diffusion models image-to-image新时代》、
GAN,VAE,Diffusion对比
GAN
优点
生成的图片逼真
缺点
由于要同时训练判别器和生成器这两个网络,训练不稳定GAN主要优化目标是使图片逼真,导致图片多样性不足GAN的生成是隐式的,由网络完成,不遵循概率分布,可解释性不强
VAE
优点
学习…

【扩散模型】如何用最几毛钱生成壁纸
通过学习扩散模型了解到了统计学的美好,然后顺便记录下我之前文生图的基础流程~
扩散模型简介
这次是在DataWhale的组队学习里学习的,HuggingFace开放扩散模型学习地址
扩散模型训练时通过对原图增加高斯噪声,在推理时通过降噪来得到原图&…
【ICLR 2023】详细解读DiffEdit:基于扩散模型的图像编辑革命性成果
Diffusion Models专栏文章汇总:入门与实战 前言:ICLR 2023的第一轮rebuttal已经放榜,这次的ICLR出现了非常多的diffusion models论文,很多工作都非常有创意,值得详细解读。这篇要介绍的是DiffEdit,这个工作取得了所有审稿人的accept肯定,无论是论文还是实验效果都非常优…
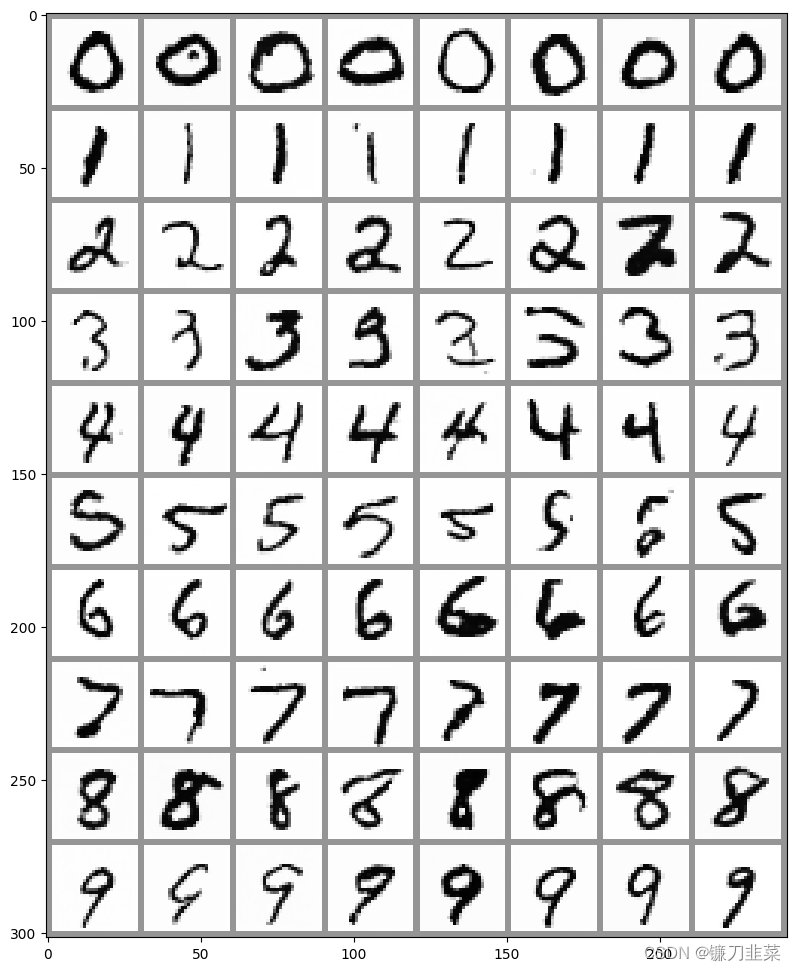
【扩散模型】实战:创建一个类别条件扩散模型
创建一个类别条件扩散模型 1. 配置和数据准备2. 创建一个以类别为条件的UNet模型3. 训练和采样 本文介绍一种给扩散模型添加额外条件信息的方法。具体地,将在MNIST数据集上训练一个以类别为条件的扩散模型。并且可以在推理阶段指定想要生成的是哪个数字。 1. 配置和…

论文阅读 - Understanding Diffusion Models: A Unified Perspective
文章目录 1 概述2 背景知识2.1 直观的例子2.2 Evidence Lower Bound(ELBO)2.3 Variational Autoencoders(VAE)2.4 Hierachical Variational Autoencoders(HVAE) 3 Variational Diffusion Models(VDM)4 三个等价的解释4.1 预测图片4.2 预测噪声4.3 预测分数 5 Guidance5.1 Class…

浅析扩散模型与图像生成【应用篇】(七)——Prompt-to-Prpmpt
7. Prompt-to-Prompt Image Editing with Cross Attention Control 本文提出一种利用交叉注意力机制实现文本驱动的图像编辑方法,可以对生成图像中的对象进行替换,整体改变图像的风格,或改变某个词对生成图像的影响程度,如下图所示…
Diffusion Models可控视频生成Control-A-Video:论文和源码解读
Diffusion Models专栏文章汇总:入门与实战 前言:Diffusion视频生成的时间连贯性问题是可控视频生成问题最大的挑战。Control-A-Video提出的时空一致性建模法、残差噪声初始化法和首帧定型法能有效解决这一问题,非常值得我们借鉴。博主详细解读论文和代码,并给出一些自己的思…

机器学习笔记 - 使用稳定扩散模型创建图像
一、简述 文本到图像生成是机器学习 (ML) 模型从文本描述生成图像的任务。目标是生成与描述非常匹配的图像,捕捉文本的细节和细微差别。这项任务具有挑战性,因为它要求模型理解文本的语义和语法,并生成逼真的图像。文本到图像生成在 AI 摄影、概念艺术、建筑建筑、时尚、视…

GANs和Diffusion模型(3)
接GANs和Diffusion模型(2)
扩散(Diffusion)模型
生成学习三重困难(Trilemma)
指生成学习(genrative learning)的模型都需要满足三个需求:
高质量的采样(High Quality Samples):模型应该能生成非常高质量的采样快速采样(Fast S…
stable diffusion model训练遇到的问题【No module named ‘triton‘】
一天早晨过来,发现昨天还能跑的diffusion代码,突然出现了【No module named ‘triton’】的问题,导致本就不富裕的显存和优化速度雪上加霜,因此好好探究了解决方案。
首先是原因,由于早晨过来发现【电脑重启】导致了【…
深度解读:如何解决Image-to-Video模型视频生成模糊的问题?
Diffusion Models视频生成-博客汇总 前言:目前Image-to-Video的视频生成模型,图片一般会经过VAE Encoder和Image precessor,导致图片中的信息会受到较大损失,生成的视频在细节信息上与输入的图片有较大的出入。这篇博客结合最新的论文和代码,讲解如何解决Image-to-Video模…
LoRA:大模型的低秩自适应微调模型
对于大型模型来说,重新训练所有模型参数的全微调变得不可行。比如GPT-3 175B,模型包含175B个参数吗,无论是微调训练和模型部署,都是不可能的事。所以Microsoft 提出了低秩自适应(Low-Rank Adaptation, LoRA),它冻结了预…

深入路径距离分析(一)
写这篇之前,整理过空间分析中的距离分析工具箱,今天继续深入的说说路径距离分析。开始路径距离分析之前,先回忆下最基本的欧式距离分析和成本距离分析。欧氏距离分析遵循的就是我们小学都知道的“两点之间直线最短”的原则,两点之…
《论文阅读》DIFFUSEMP:一种基于扩散模型的多粒度控制共情回复生成框架 2023 IEEE TAC
《论文阅读》DIFFUSEMP:一种基于扩散模型的多粒度控制共情回复生成框架 前言简介相关知识Diffusion Model模型架构整体流程Acquisition of Control SignalsDiffusion Model with Control-Range Masking损失函数实验结果问题前言
今天为大家带来的是《DIFFUSEMP: A Diffusion …

微调文本到图像扩散模型新方法DreamBooth,实现主题驱动生成(CVPR 2023)
来源:投稿 作者:橡皮 编辑:学姐 论文链接: https://arxiv.org/pdf/2208.12242
项目主页:https://dreambooth.github.io/ 图1. 只需要拍摄某个主题(左)的几张图像(通常为 3-5 张&…
【NeurIPS 2023】多模态联合视频生成大模型CoDi
Diffusion Models视频生成-博客汇总 前言:目前视频生成的大部分工作都是只能生成无声音的视频,距离真正可用的视频还有不小的差距。CoDi提出了一种并行多模态生成的大模型,可以同时生成带有音频的视频,距离真正的视频生成更近了一步。相信在不远的将来,可以AI生成的模型可…
图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer
前言
2018年我写过一篇博客,叫:《一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》,该文相当于梳理了2019年之前CV领域的典型视觉模型,比如
2014 R-CNN2015 Fast R-CNN、Faster R-CNN2016 YOLO、SSD2…
【SIGGRAPH 2023】解读Rerender A Video:Zero-Shot 视频翻译任务
Diffusion Models视频生成-博客汇总 前言:Video-to-Video是视频生成中非常火的任务,也是最有应用价值的方向。图形学顶会SIGGRAPH 2023有一篇经典论文《Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation》,其中关键帧翻译、跨帧约束等方法值得我们借鉴。…
2024年Diffusion Models还有哪些方向值得研究(好发论文)?
Diffusion Models专栏文章汇总:入门与实战 前言:笔者follow扩散模型的科研进展已经将近3年了,见证了diffusion从无人问津到炙手可热的过程。当下扩散模型还有哪些缺点?还有哪些需要改进的方向?还有哪些方向值得研究?还有哪些方向好发论文?不知不觉时间已经来到了2024年,…
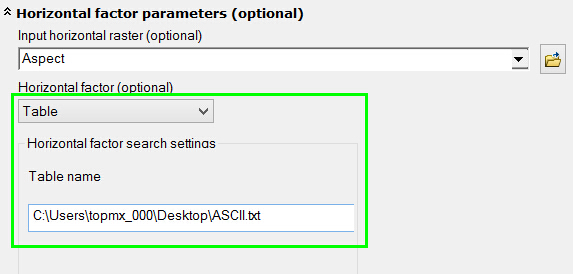
深入路径距离分析(二)
接着上一篇文章,继续说说水平影响因子:水平系数
水平系数 (HF) 从像元移动时所遇到的水平阻力因素的角度出发,确定从一个像元移到另一个像元的成本,或者说是困难。
在路径距离分析中,提供了确定水平方向成本的参数&…

NLP(6)--Diffusion Model
目录
一、Flow-Based General Model
1、概述
2、函数映射关系
3、Coupling Layer
4、Glow
二、Diffusion Model
1、概述
2、前向过程
3、反向过程
4、训练获得噪声估计模型
5、生成图片
三、马尔科夫链 一、Flow-Based General Model
1、概述 Flow-Based General…

【AI视野·今日CV 计算机视觉论文速览 第286期】Tue, 9 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Tue, 9 Jan 2024 Totally 121 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Dr$^2$Net: Dynamic Reversible Dual-Residual Networks for Memory-Efficient Finetuning Authors Chen Zhao, Shuming Li…

用通俗易懂的方式讲解:Stable Diffusion WebUI 从零基础到入门
本文主要介绍 Stable Diffusion WebUI 的实际操作方法,涵盖prompt推导、lora模型、vae模型和controlNet应用等内容,并给出了可操作的文生图、图生图实战示例。适合对Stable Diffusion感兴趣,但又对Stable Diffusion WebUI使用感到困惑的同学。…
解读DreamPose:基于Diffusion Models的模特视频生成
Diffusion Models视频生成-博客汇总 前言:谷歌研究院联合英伟达提出了DreamPose,通过修改起点噪声融入姿态信息,并微调VAE-CLIP adapter注入图片信息,做到pose&image-to-video的效果。是少数扩散模型中image-to-video的工作,这篇博客详细解读一下这篇论文《DreamPose:…
解读Sketching the Future (STF):零样本条件视频生成
Diffusion Models视频生成-博客汇总 前言:基于草图的视频生成目前是一个基本无人探索过的领域,videocomposer做过一些简单的探索。Sketching the Future从零样本条件视频生成出发,出色的完成了这一任务。这篇博客就解读一下《Sketching the Future (STF): Applying Conditio…

浅析扩散模型与图像生成【应用篇】(八)——BBDM
8. BBDM: Image-to-Image Translation with Brownian Bridge Diffusion Models 本文提出一种基于布朗桥(Brownian Bridge)的扩散模型用于图像到图像的转换。图像到图像转换的目标是将源域 A A A中的图像 I A I_A IA,映射到目标域 B B B中得…

从零开始学习Diffusion Models: Sharon Zhou
How Diffusion Models Work
本文是 https://www.deeplearning.ai/short-courses/how-diffusion-models-work/ 这门课程的学习笔记。 文章目录 How Diffusion Models WorkWhat you’ll learn in this course [1] Intuition[2] SamplingSetting Things UpSamplingDemonstrate i…

【论文笔记】Denoising Diffusion Probabilistic Models
Pre Knowledge
1.条件概率的一般形式 P ( A , B ) P ( B ∣ A ) P ( A ) P(A,B)P(B|A)P(A) P(A,B)P(B∣A)P(A) P ( A , B , C ) P ( C ∣ B , A ) P ( B , A ) P ( C ∣ B , A ) P ( B ∣ A ) P ( A ) P(A,B,C)P(C|B,A)P(B,A)P(C|B,A)P(B|A)P(A) P(A,B,C)P(C∣B,A)P(B,A)P…

【AIGC】手把手使用扩散模型从文本生成图像
手把手使用扩散模型从文本生成图像 从 DALLE 到Stable Diffusion使用diffusers package从文本prompt生成图像参考资料 在这篇文章中,我们将手把手展示如何使用Hugging Face的diffusers包通过文本生成图像。 从 DALLE 到Stable Diffusion
DALLE2是收费的,…

Stable Diffusion 3 发布及其重大改进
1. 引言
就在 OpenAI 发布可以生成令人瞠目的视频的 Sora 和谷歌披露支持多达 150 万个Token上下文的 Gemini 1.5 的几天后,Stability AI 最近展示了 Stable Diffusion 3 的预览版。
闲话少说,我们快来看看吧!
2. 什么是Stable Diffusion…
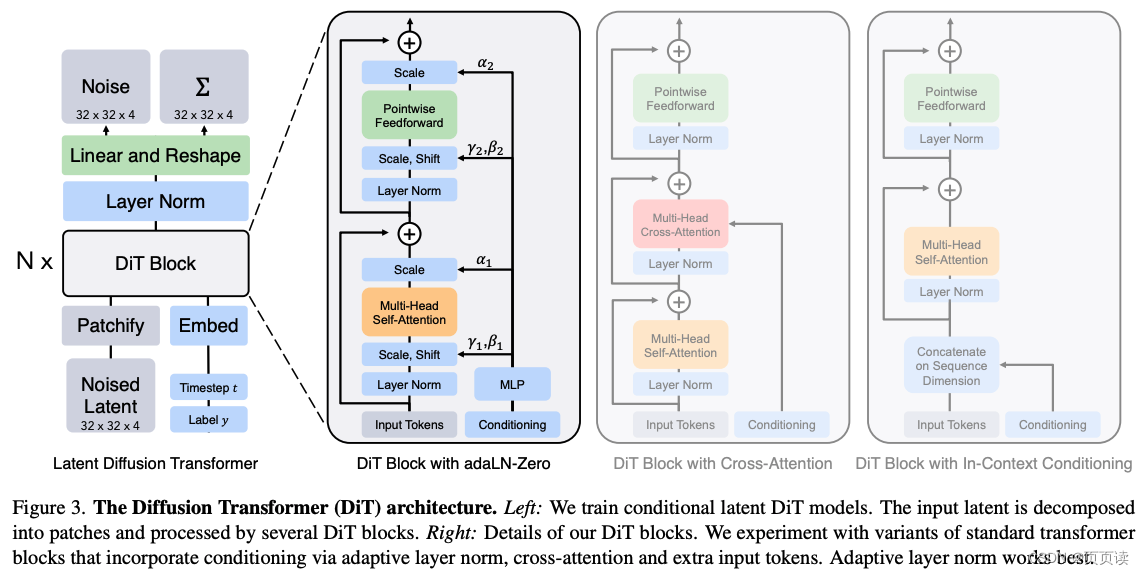
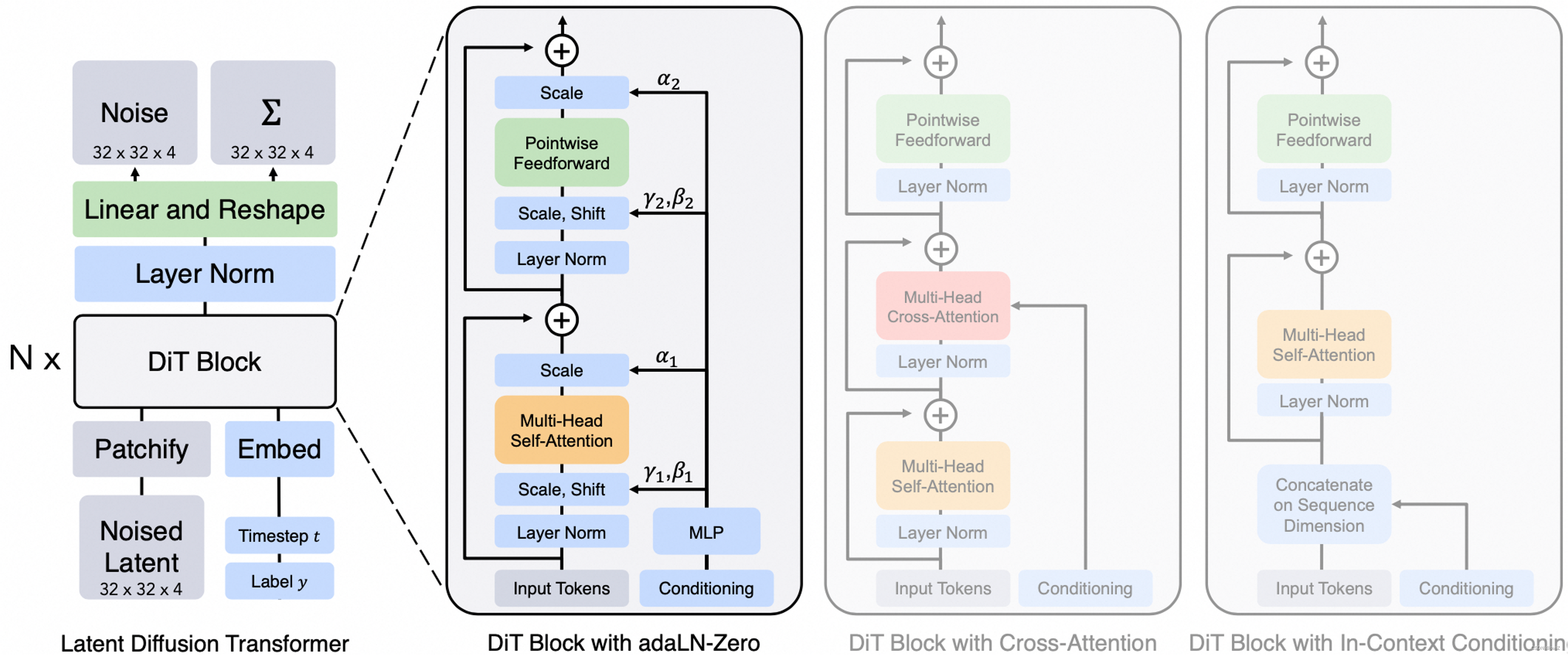
【Paper Reading】7.DiT(VAE+ViT+DDPM) Sora的base论文
VAE
DDPM 分类 内容 论文题目 Scalable Diffusion Models with Transformers 作者 William Peebles (UC Berkeley), Saining Xie (New York University) 发表年份 2023 摘要 介绍了一类新的扩散模型,这些模型利用Transformer架构,专注于图像生…

【AI视野·今日CV 计算机视觉论文速览 第285期】Mon, 8 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Mon, 8 Jan 2024 Totally 66 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Denoising Vision Transformers Authors Jiawei Yang, Katie Z Luo, Jiefeng Li, Kilian Q Weinberger, Yonglong Tian, Yue…

浅析扩散模型与图像生成【应用篇】(六)——DiffuseIT
6. Diffusion-based Image Translation using Disentangled Style and Content Representation 本文介绍了一种基于扩散模型的图像转换方法,图像转换就是根据文本引导或者图像的引导,将源图像转换到目标域中,如下图所示。 在图像转换中待…
![[PMLR 2021] Zero-Shot Text-to-Image Generation:零样本文本到图像生成](https://img-blog.csdnimg.cn/img_convert/eae8c832d9fd3e9b696a3f02bb50b96a.png)
[PMLR 2021] Zero-Shot Text-to-Image Generation:零样本文本到图像生成
[PMLR 2021]Zero-Shot Text-to-Image Generation:零样本文本到图像生成 Fig 1. 原始图像(上)和离散VAE重建图像(下)的比较。编码器对空间分辨率进行8倍的下采样。虽然细节(例如,猫毛的纹理、店面上的文字和插图中的细线)有时会丢失或扭曲,但图…

【论文阅读笔记】InstantID : Zero-shot Identity-Preserving Generation in Seconds
InstantID:秒级零样本身份保持生成 理解摘要Introduction贡献 Related WorkText-to-image Diffusion ModelsSubject-driven Image GenerationID Preserving Image Generation Method实验定性实验消融实验与先前方法的对比富有创意的更多任务新视角合成身份插值多身份区域控制合…
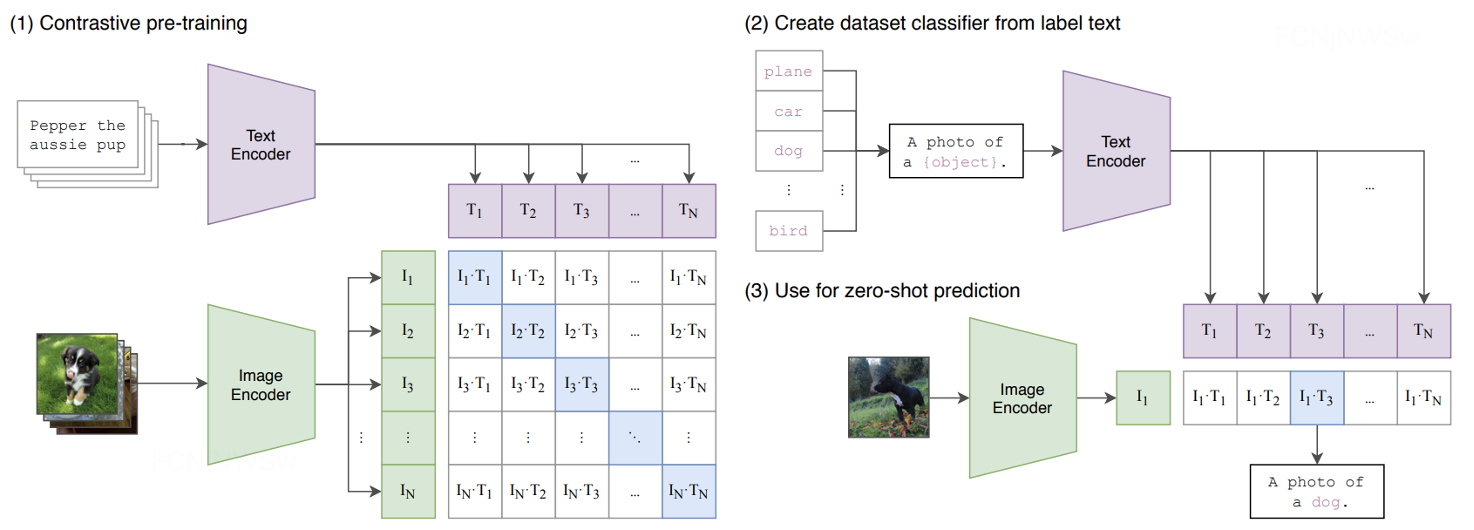
文生图大模型三部曲:DDPM、LDM、SD 详细讲解!
1、引言
跨模态大模型是指能够在不同感官模态(如视觉、语言、音频等)之间进行信息转换的大规模语言模型。当前图文跨模态大模型主要有: 文生图大模型:如 Stable Diffusion系列、DALL-E系列、Imagen等 图文匹配大模型:如CLIP、Chinese CLIP、…

解读电影级视频生成模型 MovieFactory
Diffusion Models视频生成-博客汇总 前言:MovieFactory是第一个全自动电影生成模型,可以根据用户输入的文本信息自动扩写剧本,并生成电影级视频。其中针对预训练的图像生成模型与视频模型之间的gap提出了微调方法非常值得借鉴。这篇博客详细解…
【换脸方法汇总】生成对抗网络GAN、扩散模型等
【换脸方法汇总】生成对抗网络GAN、扩散模型等 [【CVPR2022论文精读DiffFace】DiffFace: Diffusion-based Face Swapping with Facial Guidance](https://blog.csdn.net/qq_45934285/article/details/130840631?spm1001.2014.3001.5501) 【CVPR2022论文精读DiffFace】DiffFace…

基于Transformer结构的扩散模型综述
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…
AIGC实战——扩散模型(Diffusion Model)
AIGC实战——扩散模型 0. 前言1. 去噪扩散概率模型1.1 Flowers 数据集1.2 正向扩散过程1.3 重参数化技巧1.4 扩散规划1.5 逆向扩散过程2. U-Net 去噪模型2.1 U-Net 架构2.2 正弦嵌入2.3 ResidualBlock2.4 DownBlocks 和 UpBlocks3. 训练扩散模型4. 去噪扩散概率模型的采样

Stable Diffusion之最全详解图解
Stable Diffusion之最全详解图解 1. Stable Diffusion介绍1.1 研究背景1.2 学术名词 2.Stable Diffusion原理解析2.1 技术架构2.2 原理介绍扩散过程 3.1 Diffusion前向过程3.2 Diffusion逆向(推断)过程 1. Stable Diffusion介绍
Stable Diffusion是2022…
小红书多模态团队建立新「扩散模型」:解码脑电波,高清还原人眼所见
近些年,研究人员们对探索大脑如何解读视觉信息,并试图还原出原始图像一直孜孜不倦。去年一篇被 CVPR 录用的论文,通过扩散模型重建视觉影像,给出了非常炸裂的效果—— AI 不光通过脑电波知道你看到了什么,并且帮你画了…
代码解读:Zero-shot 视频生成任务 Text2Video-Zero
Diffusion Models视频生成-博客汇总 前言:上一篇博客《【ICCV 2023 Oral】解读Text2Video-Zero:解锁 Zero-shot 视频生成任务》解读了这篇论文《Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators》。这篇论文的创新点比较多,含金量很高,而…
DataWhale公开课笔记2:Diffusion Model和Transformer Diffusion
Stable Diffusion和AIGC
AIGC是什么
AIGC的全称叫做AI generated content,AlGC (Al-Generated Content,人工智能生产内容),是利用AI自动生产内容的生产方式。
在传统的内容创作领域中,专业生成内容(PGC)…

【AI视野·今日CV 计算机视觉论文速览 第257期】Fri, 29 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Fri, 29 Sep 2023 Totally 99 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Learning to Transform for Generalizable Instance-wise Invariance Authors Utkarsh Singhal, Carlos Esteves, Ameesh M…
【扩散模型】深入理解图像的表示原理:从像素到张量
【扩散模型】深入理解图像的表示原理:从像素到张量
在深度学习中,图像是重要的数据源之一,而图像的表示方式对于算法的理解和处理至关重要。本文将带你深入探讨图像的底层表示原理,从像素到张量,让你对图像表示有更清…
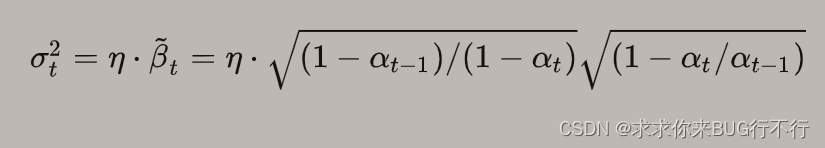
【扩散模型】 DDPM和DDIM讲解
扩散模型DDPM和DDIM
扩散模型之DDPM介绍了经典扩散模型DDPM的原理和实现,那么生成一个样本的次数和训练次数需要一致,导致采样过程很缓慢。这篇文章我们将介绍另外一种扩散模型DDIM(Denoising Diffusion Implicit Models)&#x…

浅析扩散模型与图像生成【应用篇】(四)——Palette
4. Palette: Image-to-Image Diffusion Models 该文提出一种基于扩散模型的通用图像转换(Image-to-Image Translation)模型——Palette,可用于图像着色,图像修复,图像补全和JPEG图像恢复等多种转换任务。Palette是一种…

【AI视野·今日CV 计算机视觉论文速览 第280期】Mon, 1 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Mon, 1 Jan 2024 Totally 46 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Learning Vision from Models Rivals Learning Vision from Data Authors Yonglong Tian, Lijie Fan, Kaifeng Chen, Dina K…

【扩散模型】10、ControlNet | 用图像控制图像的生成(ICCV2023)
论文:Adding Conditional Control to Text-to-Image Diffusion Models
代码:https://github.com/lllyasviel/ControlNet
出处:ICCV2023 Best Paper | 斯坦福
时间:2023.02 一、背景
文本到图像的生成尽管已经有很好的效果&…

【AI视野·今日CV 计算机视觉论文速览 第256期】Thu, 28 Sep 2023
AI视野今日CS.CV 计算机视觉论文速览 Thu, 28 Sep 2023 Totally 96 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
SHACIRA: Scalable HAsh-grid Compression for Implicit Neural Representations Authors Sharath Girish, Abhinav Shriva…

不到1s生成mesh! 高效文生3D框架AToM
论文题目: AToM: Amortized Text-to-Mesh using 2D Diffusion 论文链接: https://arxiv.org/abs/2402.00867 项目主页: AToM: Amortized Text-to-Mesh using 2D Diffusion 随着AIGC的爆火,生成式人工智能在3D领域也实现了非常显著…

Latent Diffusion(CVPR2022 oral)-论文阅读
文章目录摘要背景算法3.1. Perceptual Image Compression3.2. Latent Diffusion Models3.3. Conditioning Mechanisms实验4.1. On Perceptual Compression Tradeoffs4.2. Image Generation with Latent Diffusion4.3. Conditional Latent Diffusion4.4. Super-Resolution with …

Stable diffusion 简介
Stable diffusion 是 CompVis、Stability AI、LAION、Runway 等公司研发的一个文生图模型,将 AI 图像生成提高到了全新高度,其效果和影响不亚于 Open AI 发布 ChatGPT。Stable diffusion 没有单独发布论文,而是基于 CVPR 2022 Oral —— 潜扩…
【CVPR 2023】Diffusion Models高分辨率长视频生成 Align your Latents
Diffusion Models专栏文章汇总:入门与实战 前言:CVPR 2023年的工作《Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models》实现了高帧率高分辨率长视频生成,并在保持时间一致性上做了很多工作。这篇博客详细解读一下背后的原理,并总结一下…

使用PyTorch实现去噪扩散模型
在深入研究去噪扩散概率模型(DDPM)如何工作的细节之前,让我们先看看生成式人工智能的一些发展,也就是DDPM的一些基础研究。
VAE
VAE 采用了编码器、概率潜在空间和解码器。在训练过程中,编码器预测每个图像的均值和方差。然后从高斯分布中对…

【AI视野·今日CV 计算机视觉论文速览 第281期】Tue, 2 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Tue, 2 Jan 2024 Totally 95 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Refining Pre-Trained Motion Models Authors Xinglong Sun, Adam W. Harley, Leonidas J. Guibas考虑到在视频中手动注释运…
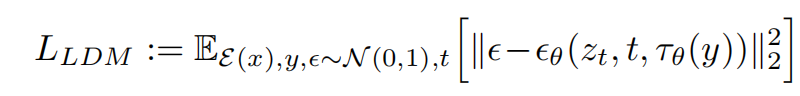
AI绘画Stable Diffusion原理之扩散模型DDPM
前言
传送门: stable diffusion:Git|论文 stable-diffusion-webui:Git Google Colab Notebook部署stable-diffusion-webui:Git kaggle Notebook部署stable-diffusion-webui:Git AI绘画,输入一段…
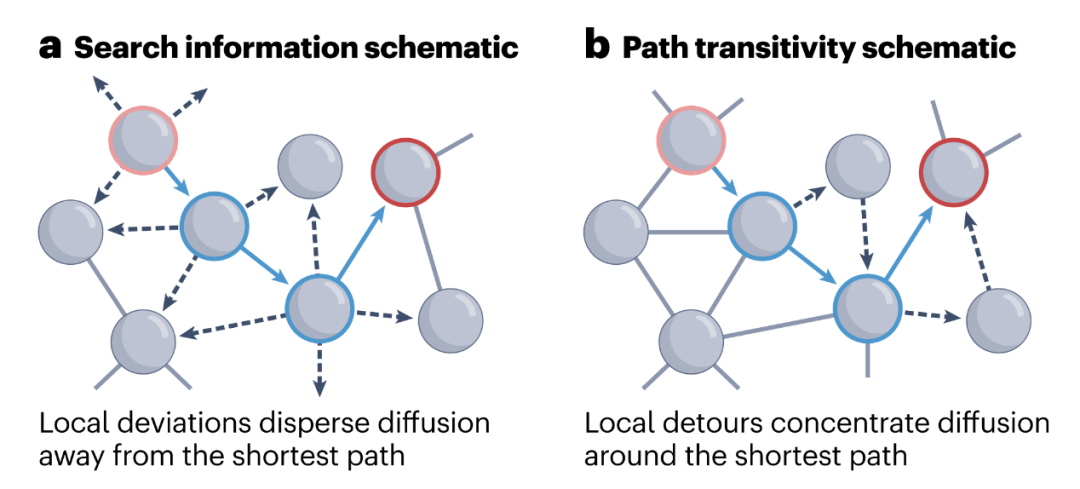
【类脑智能】脑网络通信模型分类及量化指标(附思维导图)
脑网络通信模型分类及量化指标(附思维导图)
参考论文:Brain network communication_ concepts, models and applications
概念
脑网络通信模型是一种使用图论和网络科学概念来描述和量化大脑结构中信息传递的模型。这种模型可以帮助研究人员理解神经信号在大脑内…
AI绘画神器DALLE 3的解码器:一步生成的扩散模型之Consistency Models
前言
关于为何写此文,说来同样话长啊,历程如下
我司LLM项目团队于23年11月份在给一些B端客户做文生图的应用时,对比了各种同类工具,发现DALLE 3确实强,加之也要在论文100课上讲DALLE三代的三篇论文,故此文…

Grounding DINO-开集目标检测论文解读
文章目录摘要背景算法3.1Feature Extraction and Enhancer3.2. Language-Guided Query Selection3.3. Cross-Modality Decoder3.4. Sub-Sentence Level Text Feature3.5. Loss Function实验4.2 Zero-Shot Transfer of Grounding DINOCOCO数据集LVIS数据集ODinW,开放…

扩散模型微调方法/文献综述
🎀个人主页: https://zhangxiaoshu.blog.csdn.net 📢欢迎大家:关注🔍点赞👍评论📝收藏⭐️,如有错误敬请指正! 💕未来很长,值得我们全力奔赴更美好的生活&…

0基础学习diffusion_model扩散模型【易理解的公式推导】
0基础学习diffusion_model扩散模型【易理解的公式推导】一、概述二、扩散过程(已知X0求Xt)三、逆扩散过程(已知Xt求Xt-1)1。算法流程图四、结论五、损失函数六、心得体会(优缺点分析)一、概述 DDPM论文链接: Jonathan Ho_Denoising Diffusion…
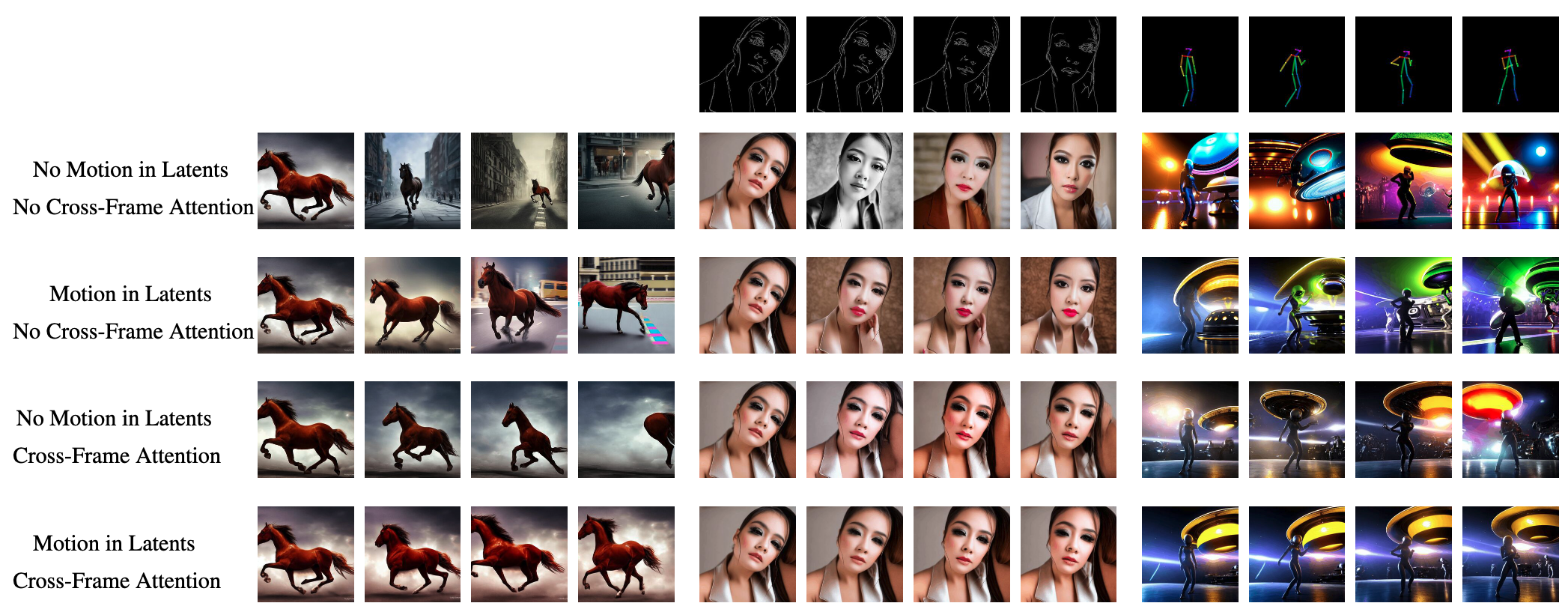
Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频生成器
Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators Paper: https://arxiv.org/abs/2303.13439 Project: https://github.com/Picsart-AI-Research/Text2Video-Zero 原文链接:Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频…
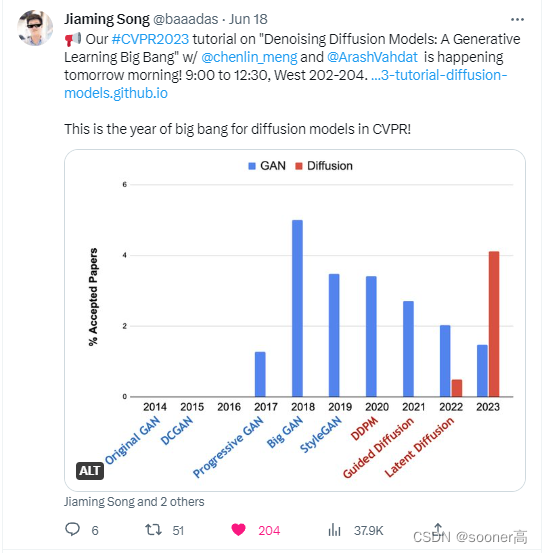
【Diffusion模型系列1】DDPM: Denoising Diffusion Probabilistic Models
0. 楔子
Diffusion Models(扩散模型)是在过去几年最受关注的生成模型。2020年后,几篇开创性论文就向世界展示了扩散模型的能力和强大:
Diffusion Models Beat GANs on Image Synthesis(NeurIPS 2021 Spotlight, OpenAI团队, 该团队也是DALLE-2的作者)[1] Various…

【AI视野·今日CV 计算机视觉论文速览 第259期】Tue, 3 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Tue, 3 Oct 2023 (showing first 100 of 167 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
GPT-Driver: Learning to Drive with GPT Authors Jiageng Mao, Yuxi Qian, Hang Zha…
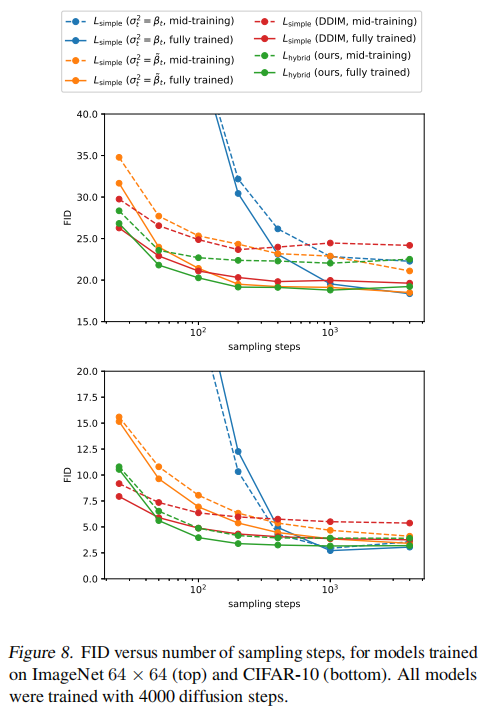
【扩散模型】4、Improved DDPM | 引入可学习方差和余弦加噪机制来提升 DDPM
文章目录 一、背景二、Improved DDPM——提升 Log-likelihood2.1 可学习的方差2.2 改进 noise schedule2.3 降低梯度噪声 三、效果 论文:Improved Denoising Diffusion Probabilistic Models
代码:https://link.zhihu.com/?targethttps%3A//github.com…

【AI视野·今日Sound 声学论文速览 第四十一期】Thu, 4 Jan 2024
AI视野今日CS.Sound 声学论文速览 Thu, 4 Jan 2024 Totally 8 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers
Multichannel blind speech source separation with a disjoint constraint source model Authors Jianyu Wang, Shanzheng Guan多通道卷积…
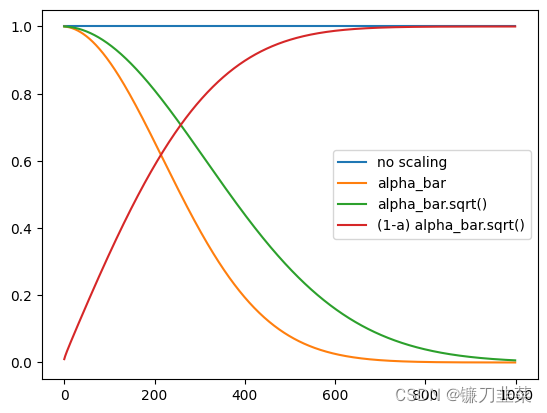
【扩散模型】理解扩散模型的微调(Fine-tuning)和引导(Guidance)
理解扩散模型的微调Fine-tuning和引导Guidance 1. 环境准备2. 加载预训练过的管线3. DDIM——更快的采样过程4. 微调5. 引导6. CLIP引导参考资料 微调(Fine-tuning)指的是在预先训练好的模型上进行进一步训练,以适应特定任务或领域的过程。这…

Diffusion:通过扩散和逆扩散过程生成图像的生成式模型
在当今人工智能大火的时代,AIGC 可以帮助用户完成各种任务。作为 AIGC 主流模型的 DDPM,也时常在各种论文中被提起。DDPM 本质就是一种扩散模型,可以用来生成图片或者为图片去噪。
扩散模型定义了一个扩散的马尔科夫过程,每一步逐…

挑战没有免费的午餐定理?南洋理工提出扩散模型增强方法FreeU
论文名称:FreeU: Free Lunch in Diffusion U-Net 文章链接:https://arxiv.org/abs/2309.11497 代码仓库:https://github.com/ChenyangSi/FreeU 项目主页:https://chenyangsi.top/FreeU 机器学习领域中一个著名的基本原理就是“没…

Vox-E: Text-guided Voxel Editing of 3D Objects(3D目标的文本引导体素编辑)
Vox-E: Text-guided Voxel Editing of 3D Objects (3D目标的文本引导体素编辑) Paper:https://readpaper.com/paper/1705264952657440000
Code:http://vox-e.github.io/
原文链接:Vox-E: 3D目标的文本引导体素编辑 &…

Amazon Generative AI 新世界 | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此&#x…
AI绘画能力的起源:通俗理解VAE、扩散模型DDPM、DETR、ViT/Swin transformer
前言
2018年我写过一篇博客,叫:《一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》,该文相当于梳理了2019年之前CV领域的典型视觉模型,比如
2014 R-CNN2015 Fast R-CNN、Faster R-CNN2016 YOLO、SSD2…
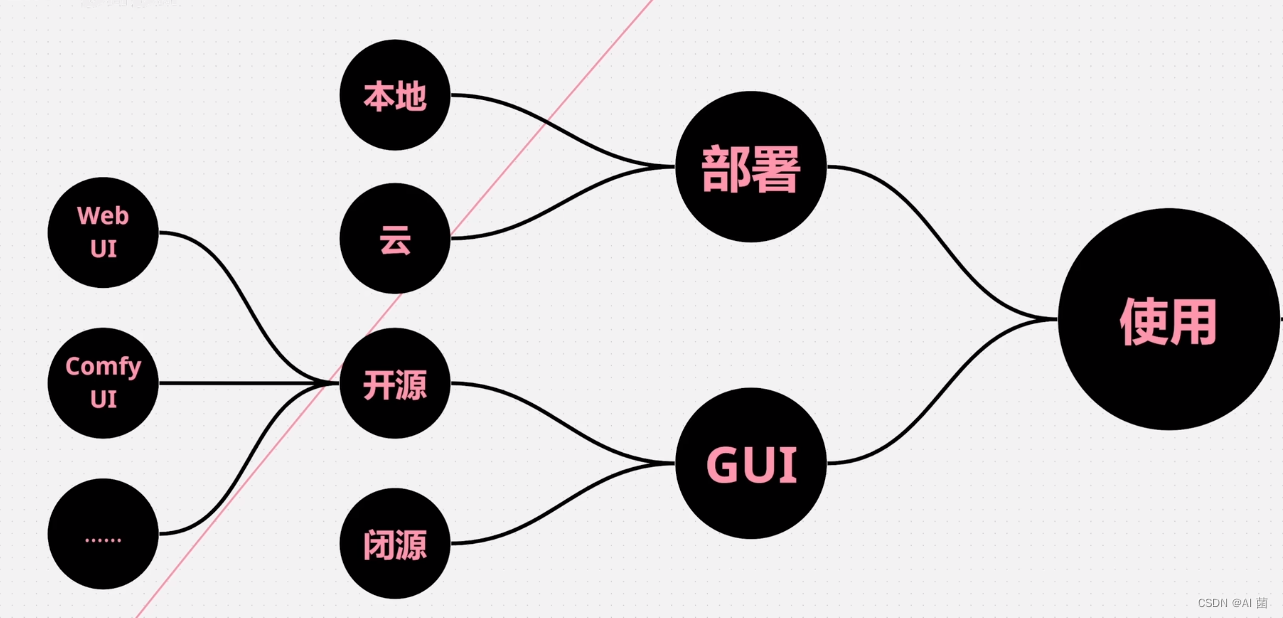
最强文生图跨模态大模型:Stable Diffusion
文章目录 一、概述二、Stable Diffusion v1 & v22.1 简介2.2 LAION-5B数据集2.3 CLIP条件控制模型2.4 模型训练 三、Stable Diffusion 发展3.1 图形界面3.1.1 Web UI3.1.2 Comfy UI 3.2 微调方法3.1 Lora 3.3 控制模型3.3.1 ControlNet 四、其他文生图模型4.1 DALL-E24.2 I…

第一章-扩散模型的基础知识
目录 简介扩散理论基础一种简单的Corruption损坏过程基础UNet训练模型采样 与 DDPM 做比较模型损坏过程训练目标采样 简介
扩散模型(Diffusion Models)在不同的领域和文献中可能有不同的名称。其中一些常见的名称包括去噪扩散概率模型(ddpm&…
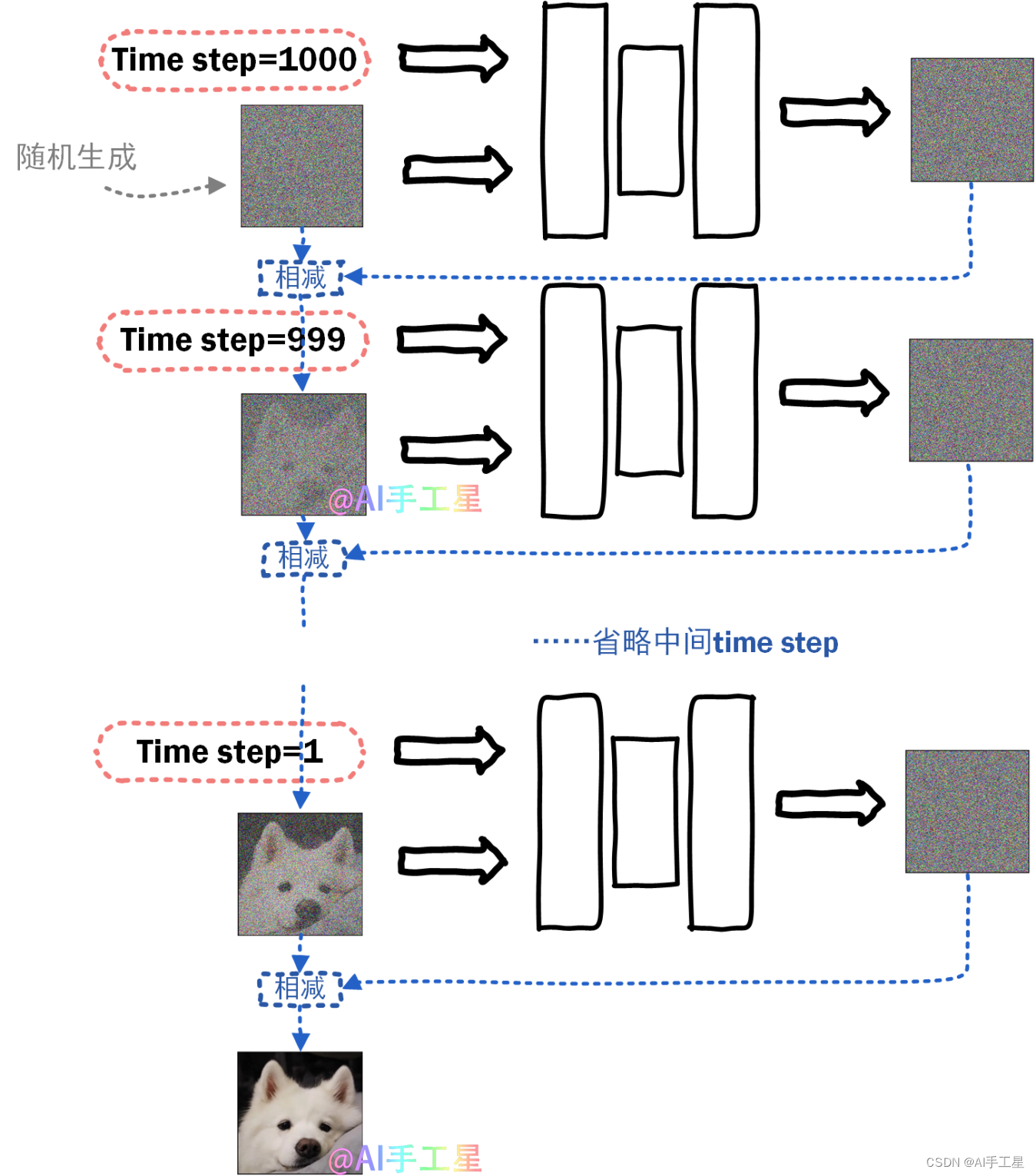
AIGC入门系列1:感性的认识扩散模型
1、序言
大家好,欢迎来到AI手工星的频道,我是专注AI领域的手工星。AIGC已经成为AI又一个非常爆火的领域,并且与之前的AI模型不同,AIGC更适合普通人使用,我们不仅可以与chatgpt对话,也能通过绘画模型生成想…
文生视频领域SOTA工作Make-A-Video:论文解读和代码赏析
Diffusion Models专栏文章汇总:入门与实战 前言:2022年年底Meta AI提出了Make-A-Video,一年过去了依旧是文生视频领域的SOTA工作,在主流数据集上依旧保持着最先进的指标。论文利用了预训练的Text-to-Image模型扩展到Text-to-Video任务,大大降低了视频生成的门槛;论文中提…
基于片段的3D分子生成扩散模型 - AutoFragDiff 评测
AutoFragDiff 是一个基于片段的,自回归的,口袋条件下的,3D分子生成扩散模型。
AutoFragDiff方法来源于文章《Autoregressive fragment-based diffusion for pocket-aware ligand design》,由加州大学的Mahdi Ghorbani等人于2023年…

Stable Diffusion系列(五):原理剖析——从文字到图片的神奇魔法(扩散篇)
文章目录 DDPM论文整体原理前向扩散过程反向扩散过程模型训练过程模型生成过程概率分布视角参数模型设置论文结果分析 要想完成SD中从文字到图片的操作,必须要做到两步,第一步是理解文字输入包含的语义,第二步是利用语义引导图片的生成。下面…
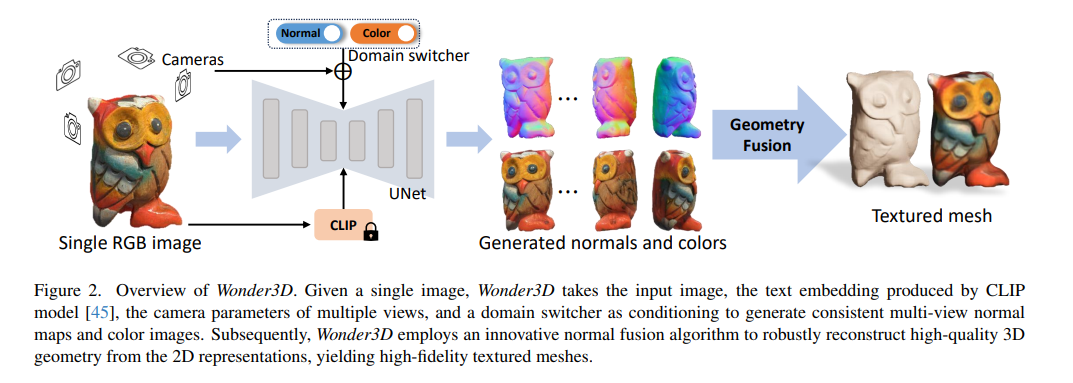
【AI视野·今日CV 计算机视觉论文速览 第274期】Tue, 24 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Tue, 24 Oct 2023 Totally 138 papers 👉上期速览✈更多精彩请移步主页 Interesting:
📚Wonder3D, 基于交叉扩散模型的单图像三维形状生成。(from 香港大学) website:https://www.xxlong.site/Wonder3D/ Daily Co…
Amazon Generative AI | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此&#x…
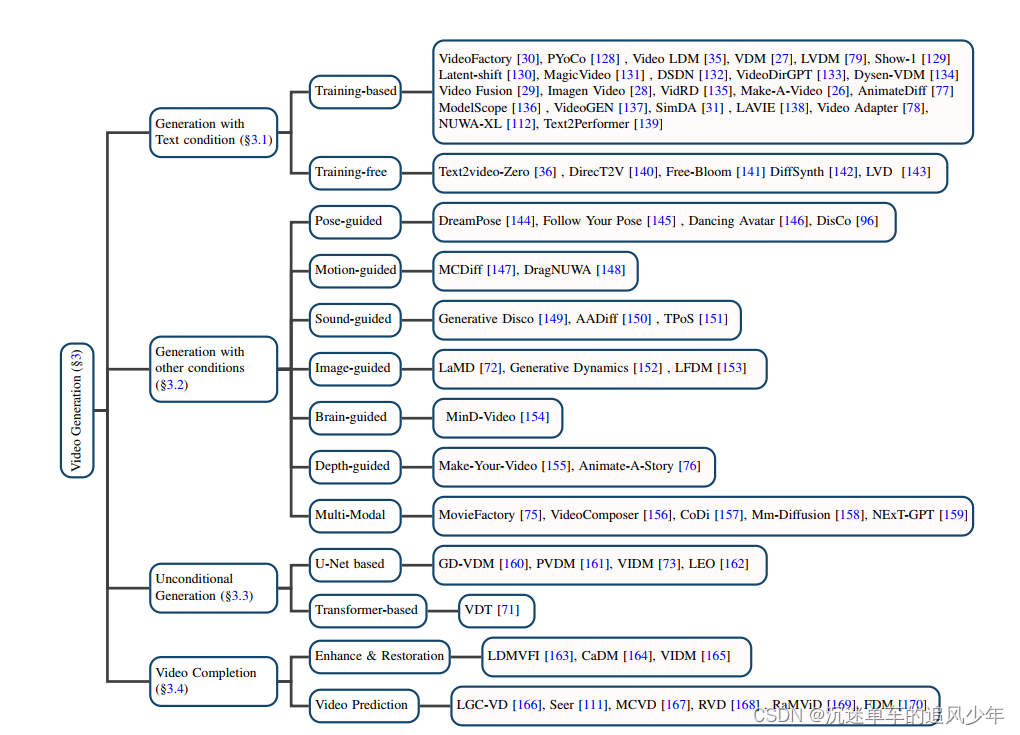
Diffusion Models视频生成-博客汇总
0、【论文汇总】Diffusion Models视频生成/视频编辑/可控视频生成/跨模态视频生成 本文总结了Diffusion Models视频生成领域相关的工作,目前共收录142篇,持续更新中。 1、Video Diffusion Models:基于扩散模型的视频生成 扩散模型已经被广泛运用到图像生成、image-to-image转…

扩散模型的Prompt指南:如何编写一个明确提示
Prompt(提示)是扩散模型生成图像的内容来源,构建好的提示是每一个Stable Diffusion用户需要解决的第一步。本文总结所有关于提示的内容,这样可以让你生成更准确,更好的图像
一个好的提示
首先我们看看什么是好的提示…
解读VideoComposer:多模态融合视频生成
Diffusion Models视频生成-博客汇总 前言:达摩院出品的VideoComposer,是Composer家族的重要成员,开辟了组合多种模态特征生成视频的先河。重要的是开源了推理代码和模型,利于后人研究。这篇博客详细解读一下VideoComposer论文原理。 目录
贡献概述
方法详解
多模态特征融…


【AI视野·今日CV 计算机视觉论文速览 第282期】Wed, 3 Jan 2024
AI视野今日CS.CV 计算机视觉论文速览 Wed, 3 Jan 2024 Totally 70 papers 👉上期速览✈更多精彩请移步主页 Daily Computer Vision Papers
Street Gaussians for Modeling Dynamic Urban Scenes Authors Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiya…

【扩散模型】不同组件搭积木,获得新模型
学习地址: https://github.com/huggingface/diffusion-models-class/tree/main/unit3
VAE The Tokenizer and Text Encoder UNet In-Painting 例如:基于contrlnet做的校徽转图片